While standardized tools can capture observable outcomes, they often miss the internal drivers such as motivation, perception, and hesitation that shape real decision-making in development. In work with smallholder farmers in China, survey responses offered little insight into these processes, underscoring the need of behavioral approaches that reveal under-measured dimensions of change.
While standardized tools can capture observable outcomes, they often miss the internal drivers such as motivation, perception, and hesitation that shape real decision-making in development. In work with smallholder farmers in China, survey responses offered little insight into these processes, underscoring the need of behavioral approaches that reveal under-measured dimensions of change.
Behavioral tools in evaluation: From margins to mainstream
This gap is now becoming acknowledged throughout the field. The UN Secretary General’s Guidance Note on Behavioral Science urges agencies to “explore and apply behavioral science in programmatic and administrative areas,” and the 2025 UN Behavioral Science Week showcased work across 46 UN agencies, spanning climate, digital inclusion, and social protection. These tools are no longer niche-they are becoming institutional.
The World Bank’s eMBeD (Mind, Behavior, and Development) unit embedded behavioral insights into evaluations in over 70 countries, helping teams move beyond surface-level indicators to uncover how people make decisions under real constraints. Meanwhile, FAO’s Self-Evaluation and Holistic Assessment of Climate Resilience of Farmers and Pastoralists (SHARP+ ) unitiative adapted household surveys by integrating behavioral questions to understand why farmers adopted or resisted certain agricultural practices. Instead of stopping at uptake rates, the evaluation explored the perceptions, trade-offs, and mental models driving actual choices. These shifts reflect a broader recognition: we cannot understand impact if we do not understand behavior.
When standard tools fall short
Despite this momentum, traditional behavioral evaluation tools, especially standardized surveys, often struggle to capture how people think and behave. This is not just about poor wording of questions-it reflects a structural misalignment between rigid instruments and real-world complexity.
Many behavioral or attitudinal questions used in evaluations are originated in and for Western, Educated, Industrialized, Rich, and Democratic (WEIRD) populations, assuming that respondents are familiar with abstract constructs, individualistic logic, and formal decision-making frameworks. However, these assumptions often do not hold in contexts where most development programs operate. In rural settings, for example, concepts such as ‘individual agency’ or ‘risk preference’ may not translate meaningfully into daily life or local language. Respondents may struggle to interpret abstract survey items or Likert-scale formats, not due to a lack of capacity, but because the framing is culturally distant and cognitively foreign.
This comprehension gap is compounded by social desirability bias. In tight-knit communities where status, face-saving, or deference to authority matter deeply, people tend to tailor responses to align with what they believe is expected. As a result, answers may reflect social norms more than actual beliefs or intentions—masking the very behaviors that evaluations aim to understand.
Behavioral measurement re-imagined as a game
In my own work, these limitations were not theoretical-they were field realities. We set out to measure risk preferences among smallholder farmers in Shanxi and nomadic herders in Inner Mongolia. Risk preference is a critical factor in rural development: it influences whether farmers adopt new technologies, invest in inputs, diversify income, or engage with formal insurance and credit systems. Likert-scale surveys, however, proved inadequate. Respondents struggled with abstract language, and answers often felt cautious or inconsistent, likely shaped by misunderstanding or social expectations.
So, I built something different: a WeChat-based behavioral game using the Balloon Analogue Risk Task (BART), a well-established experiment that measures risk-taking through gameplay. In this simple experiment, players inflate a virtual balloon to earn rewards, risking it popping with each pump. It does not ask about risk—it reveals it through behavior under uncertainty.
Embedded in a WeChat mini-program, the tool became accessible on any internet-enabled phone—no downloads or technical knowledge required. A UX designer helped simplify the interface for older, low-literacy users (Figure 1); and a developer managed backend data collection and real-time monitoring. Enumerators could walk respondents through the game in minutes (Figure. 2).
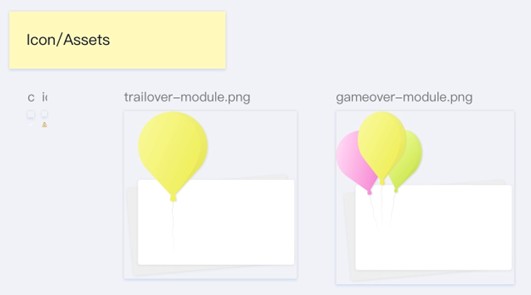
Figure 1.Visual assets for the mobile BART game used in the evaluation.
These colorful balloon modules provided visual feedback tied to participants’ risk-taking behavior.

Figure 2. In-game interface: Players press the green button to inflate the balloon or cash out.
Why behavioral tasks worked better than surveys
- No abstract reasoning: Participants simply played.
- Reduced response bias: No need to self-report or justify choices.
- Lowered barriers: Familiar app, intuitive design.
- Direct behavioral data: Observed decisions under real stakes.
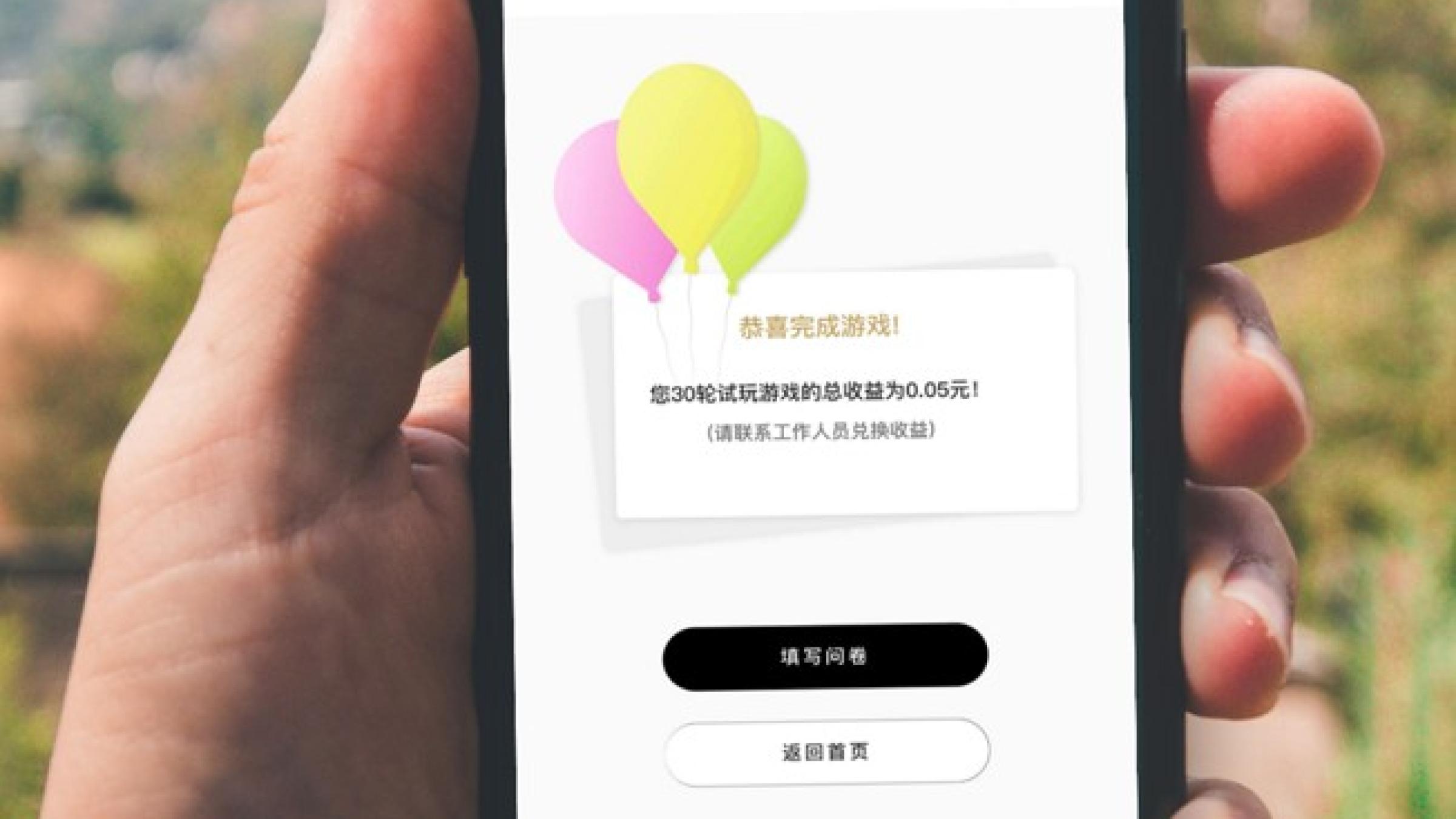
Respondents found it engaging, some even asked to play again (Figure 3). More than a data tool, the game opened space for dialogue, making evaluation feel less extractive and more collaborative. Data showed how behavioral tools, when co-designed and embedded locally, can transform the evaluation experience itself.

Figure 3. Game results screen displayed on a respondent’s phone, showing the final payout from the task.
AI as an enabler for fast, low-Cost evaluation tools
What made this possible was not just a new approach, it was accessible technology. While building such tools once required a full tech team, AI now makes it easier to prototype behavioral measurements with minimal coding expertise. One key example is vibe coding,[1] a workflow where users describe what they want in plain language, and AI helps generate the underlying code. For example, an evaluator can prompt: “Build a task where users allocate tokens between a personal and a shared account, to measure cooperative decision-making.” AI can return a working Python script, which the evaluator can then test, adapt and refine.
Platforms such as Hugging Face (e.g., with tools Gradio or Streamlit) can turn such code into deployable, interactive web apps, while Figma enables non-coders to visually mock up user interfaces for tasks and assessments. Together, these tools make it possible to move rapidly from concept to prototype and at low cost, even without a dedicated coding or design team. While some technical understanding is still needed, tasks that once required multiple experts can now be handled by one person with beginner-level skills, cutting time, cost, and complexity.
Rethinking behavior, re-writing evaluation
If we want to understand behavior in development, we need tools that reflect it. Standardized surveys built on assumptions will not get us there. To make evaluation more inclusive, credible, and future-ready, we need methods grounded in how people actually make decisions in development.
From a mobile game in rural China to behavioral diagnostics across the UN and World Bank, it is clear that evaluation is evolving. The next step is to creatively expand our toolkit: explore behavioral measurements in field settings, use AI to ease tool design, and open space for co-creation with communities we seek to understand.
[1] Vibe coding is an emerging term for using AI to translate natural language instructions into functioning code, allowing non-experts to generate and adapt scripts through platforms like OpenAI (ChatGPT + code interpreter), Hugging Face Spaces, or Streamlit apps.